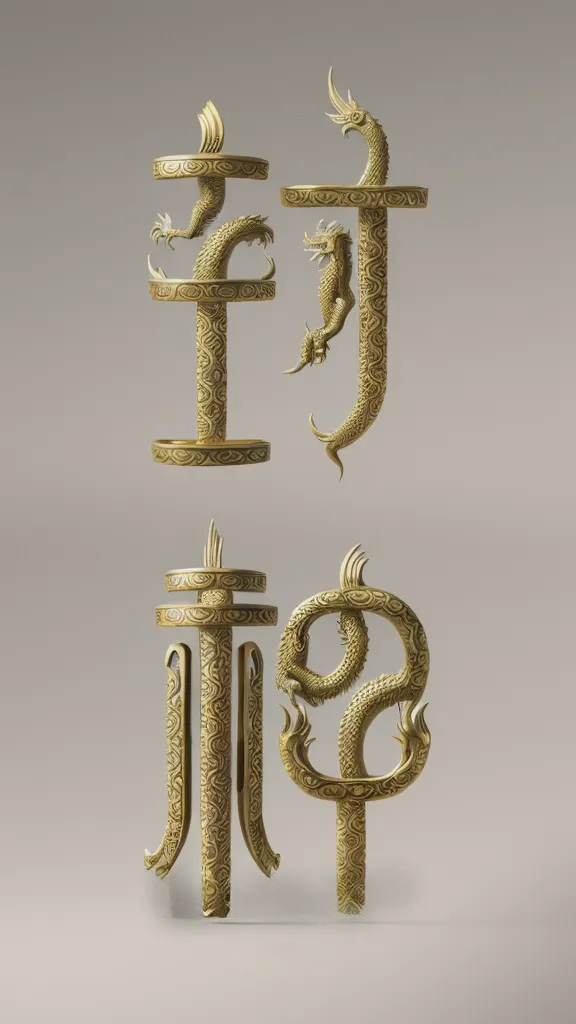角色骨骼绑定
利用了 ControlNet 的 OpenPose 功能,将姿态控制和外观/风格控制分离开。
通过提供一张参考图,让 OpenPose 预处理器提取出纯粹的骨骼姿态信息(火柴人)。
再通过文本提示词和 LoRA 来描述希望生成的角色的外观、服装和艺术风格。
在 Stable Diffusion 生成图像时,ControlNet 模型会读取骨骼图,并强制让正在生成的角色摆出相同的姿态,而角色的具体样子则由提示词和 LoRA 决定。通过调整 ControlNet 的权重和起止步数,可以控制姿态的精确度和最终效果的自然度。
分镜制作
运用阿里开发的模型in-context lora 比较适合做短视频镜头分镜的,基本上可以解决人物,服装、场景的上下文一致性。
电影故事版技巧:
用“<”和“>”括起来的占位符角色名称在图像中唯一地引用该角色的身份,确保在整个故事板中角色形象的一致性。可以写一个场景,他们每个人只用一段话。严格遵循这个格式,会保持分镜头的一致性
【SCENE-1】显示<name>做某事
【场景-2】
切换到<名字>做其他事情,并展示这个人的面部细节。
【场景-3】 描述<名字>看着美丽的事物,展示更多环境的细节。
艺术字设计
精准文字塑形: ControlNet (Canny) 是核心技术,确保生成的艺术效果严格保持输入文字的可读性和基本形态。
丰富风格融合: 通过叠加多个 LoRA 模型,可以混合多种复杂的艺术风格、材质和主题元素,创造出独特的视觉效果。
主题场景生成: 不仅仅是给文字上色或加纹理,而是将文字本身作为场景的主体或构成元素,生成完整的艺术画面。
高可控性: 用户可以通过更换输入文字图像、调整 LoRA 组合与权重、修改提示词、选择不同的 ControlNet 模型/预处理器来精确控制最终效果。
高质量输出: 包含了 Ultimate SD Upscale 步骤,能够生成适合印刷或展示的高分辨率图像。